Corona-Board-Crawling-Method-Decision
웹페이지 종류별 크롤링 방식 결정 방법
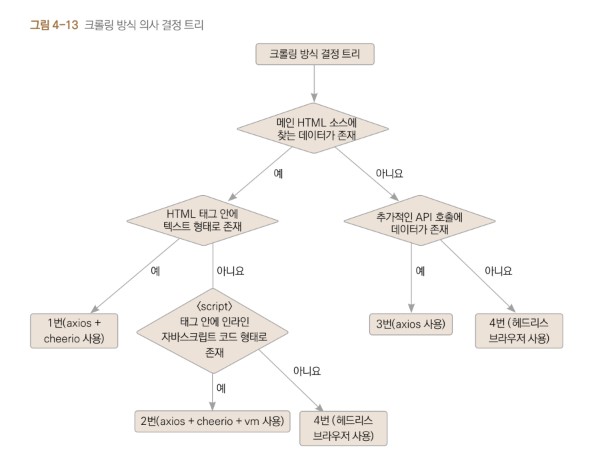
메인 HTML 소스에 찾는 데이터가 존재하는 경우(1, 2번)
1. HTML 태그 안에 텍스트 형태로 존재하는 경우
- 웹페이지 주소에서 HTML을 불러온 후 cheerio를 이용해 요소를 찾아내는 방식을 사 용하면 됩니다.
2. script 태그 안에 자바스크립트 코드로 데이터가 하드코딩 된 경우
- script 태그 안에 자바스크립트 코드를 인라인inline으로 작성하면 페이지가 로드되 면서 자동으로 실행됩니다. 이곳에 변수를 선언해 자바스크립트 코드 형태로 원하는 데이터를 하 드코딩해두면, 언제든 해당 변수에 접근해 데이터를 읽을 수 있습니다.
3. API를 호출해서 외부에서 데이터를 불러오는 경우
웹브라우저로 웹페이지를 불러올 때는 분명히 찾는 데이터가 있는데 HTML 소스 보기를 하면 없는 경우도 자주 있습니다. 보통 웹페이지 어딘가에서 API를 호출해서 추가로 데이터를 불러오기 때문일 가능성이 높습니다.
메인 HTML 내부에 기본 콘텐츠가 있고 일부 데이터는 동적으로 불러오는 웹사이트가 이에 해당 합니다.
- 웹페이지에서 사용하는 API는 일반적으로 HTTP 기반의 API를 많이 사용하므로 이런 API 호출이 일어났는지부터 확인해야 합니다.
- 이때 크롬 [개발자 도구]의 [Network] 탭이 아주 유용합니다.
그래도 데이터가 안 나온다면?
데이터가 자바스크립트 코드 내에 존재하지만 해당 데이터에 접근하는 명확한 경로를 알 수 없는 경우
실제 규모 있는 웹페이지에서는 script 태그에서 별도의 자바스크립트 파일을 읽어들여서 실행하는 방식을 더 많이 사용
- 이때에도 전역 변수가 사용된다면 해당 자바스크립트 파일의 코드를 vm 라이브러리를 통해 실행한 후 전역 변수에 접근하여 사용하면 됩니다.
반면 전역 변수가 아니 라 자바스크립트 파일 깊숙한 곳에 존재하는 변수라면 접근이 어렵습니다.
보안을 강화할 목적으로 데이터를 암호화/인코딩encoding해서 전달을 하는 경우
이 경우에는 [Network] 탭에서 원하는 텍스트를 검색하더라도, 데이터가 평문이 아니기 때문에 검색되지 않습니다.
- 이런 경우에는 해당 페이지에서 사용하는 자바스크립트에 포함된 관련 코드 를 분석하여 주고받는 데이터를 복호화/디코딩decoding해야 합니다.
위 두 가지 경우에는 결국 실제로 웹브라우저로 해당 웹페이지를 열고, 웹페이지의 렌더링이 완료 되기를 기다린 후 웹브라우저에 로드된 DOM에서 원하는 데이터를 찾아서 추출
HTTP API 통신이 아닌 웹소켓WebSocket 등을 이용한 소켓 통신 방식으로 데이터를 주고받는 경우
웹소켓 통신 내용은 [개발자 도구]의 [Network] 탭 에 잘 나타나기 때문에 데이터의 존재 여부 확인은 쉽습니다.
- 크롤링하고자 하는 웹소켓 통신의 요청/응답 내용을 잘 분석하여 어떤 식으로 데이터를 주고받는지를 정확히 파악해야 합니다.
- 그 후 원하는 데이터를 서버에 요청하면 응답으로 해당 데이터를 받게 되고, 이 응답에서 원하 는 데이터를 추출하는 식으로 크롤러를 구현
4. 헤드리스 브라우저를 이용한 크롤링
헤드리스 브라우저headless browser란 GUI 없이 CLI에서 실행되는 웹브라우저입니다.
헤드리스 브라우저를 사용하면 CLI 환경에서 웹페이지 의 스크린샷을 생성한다든가, 해당 웹페이지의 특정 버튼을 눌러서 의도한 대로 동작이 잘 되는지 테스트를 해본다든가 하는 자동화 작업을 편리하게 할 수 있습니다.
크롬 개발팀에서 만든 puppeteer 라이브러리를 사용하면 크롬 브라우저의 모든 기능을 제어할 수 있습니다. 페이지가 완전히 로드되기를 기다렸다가 완성된 DOM에서 원하는 데이터를 찾으면 되죠. 이 방식을 사용 하면 데이터가 어디에 존재하는지 일일이 네트워크 요청을 뒤질 필요가 없습니다. 일반 웹브라우저에서 사용자가 보는 웹페이지에 우리가 찾는 데이터가 있다면 헤드리스 브라우저에서도 우리가 찾는 데이터가 동일한 위치에 존재할 것이기 때문입니다.
waitUntil 옵션
waitUntil 옵션을 주면 해당 주소에 대한 웹페이지 로드 코드를 수행한 후 다음 코드를 실행하기 전에 얼마나 기다릴지를 정할 수 있습니다.
-
domcontentloaded : 메인 HTML이 로드되어 DOM이 생성된 순간까지 기다립니다. 포함된 리소스의 로드는 기다리지 않기 때문에 찾는 내용이 메인 HTML 자체에 존재하는 경우 유용 합니다.
-
load : 메인 HTML과 포함된 자바스크립트, CSS, 이미지 등 모든 리소스가 로드될 때까지 기다립니다.
-
networkidle0 : 최소 500ms 동안 활성화된 네트워크 연결이 완전히 없어질 때까지 기다립니다. 자바스크립트를 사용한 API 요청이 있는 페이지에 유용합니다.
-
networkidle2 : 최소 500ms 동안 활성화된 네트워크 연결이 2개 이하로 유지될 때까지 기다립니다. 웹페이지 로드가 완료된 이후에도 주기적으로 정보를 업데이트하는 등 폴링 방식으로 구현된 웹페이지에 적용하면 유용합니다.
폴링(polling): 외부 상태를 확인할 목적으로 주기적으로 검사를 수행하는 방식. 클라이언트/서버 환경에 적용하면 보통 클라이언트가 서 버에 주기적으로 요청을 해서 새로운 정보가 있는지 확인하여 받아오는 방식을 의미합니다.
waitFor
API가 호출되고 데이터를 불러오는 과정에 시간이 걸립니다. 데이터를 불러와서 해당 내용 이 DOM을 업데이트되기 전까지는 원하는 데이터를 얻을 수 없습니다. page 객체는 작업이 완 료될 때까지 기다리는 다음과 같은 여러 함수를 제공합니다.
-
waitForTimeout : 단순히 지정한 시간만큼 기다리는 함수입니다. 네트워크 속도나 상황에 따 라 응답 속도가 달라질 수 있어서 상황에 맞게 2초에서 30초로 잡게 됩니다. 대기 시간이 길 면 크롤링 시간도 그만큼 오래 걸려서 비효율적입니다. 최대한 사용을 지양하는 것이 좋습 니다.
-
waitForFunction : 조건을 인수로 받아, 실제 웹브라우저 컨텍스트에서 실행하여 참이 될 때 까지 기다리는 함수입니다. 웹브라우저 컨텍스트에서 실행되기 때문에 웹브라우저에 전역 객체로 존재하는 document 객체에 접근하여 사용합니다. 5 id값이 content인 요소에 접 근하여 텍스트가 채워져 있는지를 확인합니다.
-
waitForSelector : CSS 셀렉터를 인수로 받고, 해당 셀렉터를 만족하는 요소가 존재할 때까지 기다리는 함수입니다. waitForFunction보다 간편하게 사용할 수 있지만 요소의 존재 여부 로만 판단하기 때문에 복잡한 조건에서는 사용이 불가능합니다.