Corona-Board-Crawler
기본적인 크롤러 만들어보기
개발 환경 설정
$ mkdir crawler $ cd crawler
$ npm init -y
$ npm install axios@0.21.1 cheerio@1.0.0-rc.9 puppeteer@9.1.1 lodash@4.17.20 date-fns@2.21.1 date-fns-tz@1.1.4
-
axios : HTTP 호출을 더 편리하게 해주는 HTTP 클라이언트 라이브러리입니다. 이를 이 용하여 웹브라우저가 특정 URL로부터 웹페이지 HTML을 로드하듯이 크롤러에서도 특정 URL의 HTML을 로드할 수 있습니다.
-
cheerio : 로드된 HTML을 파싱하여 DOM을 생성하는 라이브러리입니다. 웹브라우저에서 제공하는 DOM 인터페이스와는 사용 방법이 좀 다르지만 구현된 기능 자체는 대부분 비슷 해 CSS 셀렉터 문법을 사용한 검색이 가능합니다.
-
puppeteer : 헤드리스 브라우저(4.4.3절 참조)를 프로그래밍 방식으로 조작하는 라이브 러리입니다. puppeteer 설치와 함께 최신 버전의 크로미움Chromium이 자동으로 node_ modules/puppeteer 경로 내부에 기본 설치됩니다.
-
lodash : 자바스크립가 기본 제공하지 않는 다양한 유틸리티 함수를 모아둔 라이브러리입니다.
-
date-fns, date-fns-tz : 자바스크립트가 제공하는 Date 객체는 날짜/시간의 타임존 변환이 나 원하는 날짜 형식으로 변환이 어렵습니다. 이를 해결해주는 라이브러리입니다.
const axios = require('axios');
const cheerio = require('cheerio');
async function main(){
// 1 HTML 로드하기
const resp = await axios.get(
'https://yjiq150.github.io/coronaboard-crawling-sample/dom'
);
/*axios.get( ) 함수는 웹페이지에 HTTP GET 요청을 보내서 HTTP 응답을 받습니다.
*resp 객체의 data 필드를 통해서 응답받은 HTML 내용에 접근할 수 있습니다.
* HTML 응답 내용은 웹 브라우저로 열었을 때와 완전히 동일합니다.*/
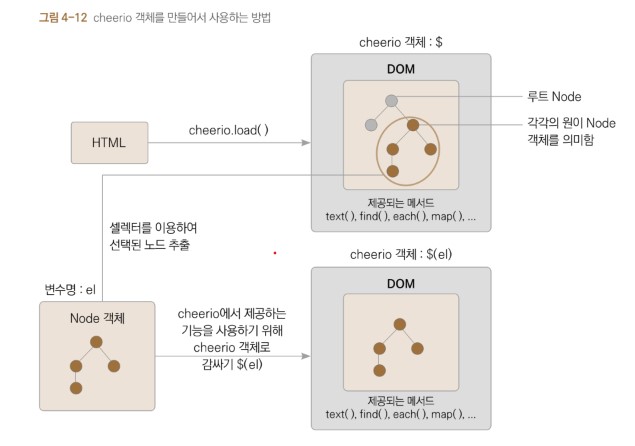
const $ = cheerio.load(resp.data); // 2 HTML을 파싱하고 DOM 생성하기
const elements = $('.slide p'); // 3 CSS 셀렉터로 원하는 요소 찾기
/*
노드JS 런타임은 웹브라우저가 아니므로 해당 HTML 내용을 자동으로 파싱하여 DOM을 만들어 주지는 못합니다.
그래서 2 cheerio 라이브러리를 이용하여 DOM을 만들어줍니다.
cheerio.load( )를 통해 DOM을 구성한 후 cheerio 객체 형태로 반환해줍니다.
이렇게 반환된 cheerio 객체는 내부에 DOM 정보를 모두 가지고 있습니다.
생성된 cheerio 객체는 관행적으로 $ 변수 에 저장해 사용합니다.
이렇게 변수 이름을 지정하면 3 CSS 셀렉터로 원하는 요소를 찾을 때도 $('.slide p') 형식으로 호출할 수 있어 편리합니다.
이러한 형식으로 요소를 찾는 방식은 jQuery11 에서부터 사용하는 오래된 관습입니다.
*/
// 4 찾은 요소를 순회하면서 요소가 가진 텍스트 출력하기
elements.each((idx, el) =>{
// 5 text() 메서드를 사용하기 위해 Node 객체인 el을 $로 감싸서 cheerio 객체로 변환
console.log($(el).text());
});
/*el 변수에 담긴 요소는 cheerio에서 만들어낸 DOM 상의 Node 객체12입니다.
이 Node 객체는 순수하게 DOM 상의 Node를 표현하는 기능만 갖고 있습니다
(웹브라우저에서 DOM을 다룰 때 존재하는 Node 객체와 기본적인 개념은 동일하지만 제공되는 기능에 차이가 있습니다).
때문에 단순히 Node 객체만 가지고는 해당 Node와 자식 Node가 가진 텍스트 내용만 손쉽게 추출할 방법이 없습니다.
하지만 이 Node 객체를 cheerio 객체13로 한 번 감싸주면 cheerio에서 제공하는 추가 기능을 사용할 수 있게 됩니다.
위 예시에서 Node와 그 자식 Node가 가진 텍스트 내 용만 추출하는 데 사용한 text( ) 함수가 바로 cheerio에서 제공되는 기능입니다.
(이러한 패턴 또 한 앞서 언급한 jQuery에서 사용하던 코드 관습을 그대로 옮겨온 겁니다)
*/
}
main();
cheerio 기본 사용법
cheerio를 이용하여 CSS 셀렉터 조건에 맞는 요소들을 찾아 순회하거나, 찾은 요소 중에 특정 요소를 선택하는 등의 처리를 하게 됩니다.
- each( ) : 찾은 요소들을 단순히 순회합니다.
- map( ) : 찾은 요소들을 순회하면서 각 요소에서 얻은 값을 이용하여 데이터를 추출하고 변환 하여, 반환값들을 모아둔 배열을 만들 수 있습니다. cheerio 객체 내부에서 사용하는 배열을 자바스크립트 배열로 변환하는 데 toArray( ) 함수를 사용합니다.
- find ( ) : 찾은 요소 를 기준 으로 새로운 조건 을 적용 하여 검색 합니다 .
- next ( ) , prev ( ) : 찾은 요소 를 기준 으로 인접한 다음 또는 이전 요소 를 찾습니다
- first ( ) , last ( ) : 찾은 요소 중 첫 번째 요소 또는 마지막 요소 를 찾습니다 .
cheerio 레퍼런스 문서 : https://cheerio.js.org/classes/cheerio.html